
byworld 님의 블로그
[MSA 요약] MSA 개념 총정리 본문
서론
다음과 같이 이미 MSA에 대해 정리한 글이 있다. 참고하여 번갈아서 보면 좋겠다.
https://byworld.tistory.com/18
[1-1 OT]
이번 강의에서는 모놀리식에서 MSA를 전환하는 내용을 듣는다. LLM의 생산성을 활용하여 대규모 트래픽을 대상으로 아키텍처를 MSA 방식으로 구현하는 것이 목표다.
[1-2 MSA]
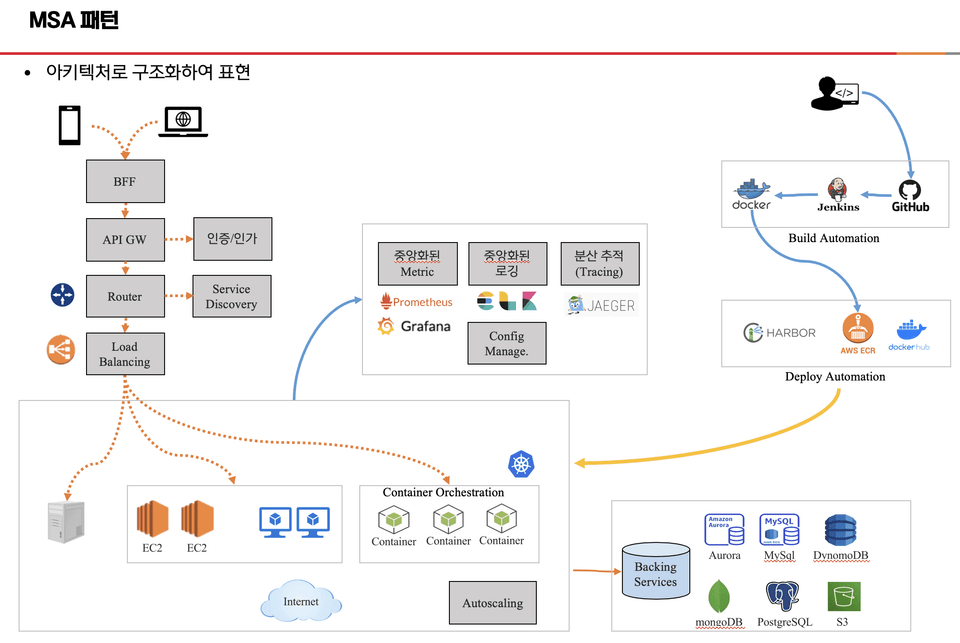
하나의 애플리케이션에 모든 기능이 존재하는 모놀리식의 방식으로는 단순하긴 하지만 대규모 트래픽을 감당하기 힘들다.
그래서 MSA(Microservices Architecture) 구조를 사용해서 기능을 서비스 단위로 분리하여 서비스 간 네트워크 통신을 한다. 각각의 어플리케이션을 독립적으로 배포가 가능하고 기술 스택 선택의 자유도(유연성)가 증가한다. 하지만 서비스의 복잡성, 운영 비용이 증가하고, 장애 전파 가능성, 데이터 불일치 가능성, HTTP(s)/큐 통신 등으로 네트워크 지연이 발생할 가능성이 있어서 관리가 필요하다.
[1-3 Spring Cloud]

스프링 클라우드는 MSA를 구현하고 운영하기 위해 다양한 인프라 기능을 제공한다. 주요 기능으로는 서비스 디스커버리(유레카), 부하를 분산하는 로드밸런싱(리본), 장애전파를 막기 위해 스위치를 여닫는 서킷브레이커(Res4j), 어떤 서비스 단위로 보내줄지, 필터를 어떻게 적용할 지등을 설정하는 API GW, 구성에 대한 관리를 해주는 구성 관리, 서비스의 흐름을 직관적으로 보여주는 분산 추적, 메시징 등을 지원한다. 다음과 같이 구조를 그려보았다.


[1-4 서비스 디스커버리]

서비스 디스커버리는 서비스의 위치(IP/Port) 를 동적으로 관리하고 찾아주는 시스템이다. 전화번호부와 비슷한 역할을 한다고 보면 된다. 그 중 Eureka를 많이 쓴다. MSA가 여러개 인스턴스를 실행할 수 있고, IP가 바뀔 수 있고, 오토스케일링을 해야하는데 유레카가 이것들을 지원해준다. 서비스 등록, 조회, 헬스 체크, 장애 인스턴스 제거 등의 기능이 존재한다. @LoadBalanced 혹은 FeignClient(강의 방식)으로 서비스 이름으로 호출이 가능하다. 서버와 first, second를 활용하여 프로젝트 3개를 만들었다.
[1-5 로드밸런싱]

로드밸런싱은 여러 인스턴스로 돌아오는 트래픽을 분산시켜 가용성과 확장성을 높인다. 여러 서버가 있어 특정 서버에 부하가 집중되는 것을 방지한다. 아마존 EC2에서 옵션으로 제공하는 기능에도 로드 밸런싱이 존재한다. 클라이언트가 직접 여러 서버 중 하나를 선택하여 요청을 보낸다. Run - Edit Configuration에 도메인을 복제하고 VM 옵션에 포트를 설정하여 같은 내용의 서버를 여러 대 둘 수 있다. FeignClient는 스프링 클라우드에서 제공하는 HTTP 클라이언트다. 선언적으로 REST 웹 서비스를 호출 가능하다. 유레카와 연동하여 동적으로 서비스 인스턴스를 조회하고 로드 밸런싱을 수행 가능하다. 로드 밸런싱 알고리즘으로는 RR(Round Robin), 가중치 기반 등이 존재한다. @FeignClient에 name 파라미터로 서비스 이름을 설정할 수 있다. 실습에서는 Product를 3개 만들어서 RR 방식으로 로드밸런싱 블랙박스 테스트를 했다.
[1-6 서킷브레이커]

서킷브레이커는 마이크로서비스 간에 호출에서 실패/지연이 누적될 시에 실패로 설정하여 장애 전파를 막고 시스템을 격리/보호 조치를 한다. 주식시장에서 급등/급락이 있을 때 정해진 기간동안 시장을 닫는 서킷브레이커와 비슷한 원리이다.
Res4j를 강의에서는 사용했다. 상태는 Closed로 모든 요청을 통과시키는 정상적 상태와, 모든 요청을 실패로 처리하는 Open, Open 후 일정 시간이 지난 후 요청이 성공할지를 테스트하고 실패하면 Open, 모두 성공하면 Closed를 설정하는 Half-Open 방식이 존재한다. 스프링 Res4j 에서는 추상화만 제공하고 구현체는 제공하지 않아 깃허브 버전으로 의존성 파일을 설정했다. @CircuitBreaker(name="이름", fallbackMethod="대체로직")으로 호출 실패 시 대체 로직을 설정한다. Fallback이라고 실패 시 대체 서비스을 제공하여 시스템 안정성을 확보한다. 사용자는 연속성이 있는 것을 원한다. 그 기능을 제공해주는 게 폴백이라고 생각하면 된다. 장애를 인지하는 것이 중요한데, 보통 슬랙같은 메신저 앱으로 팀원에게 알리나보다. 프로메테우스에서 로그를 보면 인스턴스의 상태값이 나오고, 서킷브레이커 내용도 볼 수 있다.
예시로 Order -> Payment 느릴 경우 -> Thread Blocking -> Thread Pool 고갈 -> DB Connection 고갈 -> 전체 서비스 다운
방지를 위하여 서킷브레이커 발동 -> 타임아웃 기다리지 않고 즉시 실패 반환한다.
폴백이라는 전략에서는 결제 실패 -> 주문 상태 Pending -> MQ 재시도 -> 사용자 안내 이런 식으로 사용자에게 대안을 제시한다.
Sliding window에서는 통계 기반 판단을 한다. N개 요청 기반으로 상태 판단을 하는 원리다(Half-open Test).
이벤트 리스너는 단순 로그가 아니라 관찰 가능성(Observability)가 핵심이다.
추가적으로 서킷브레이커+Retry 조합, 동기+비동기 비교(Feign+CircuitBreaker vs Kafka), 분산 트랜잭션 연결 (Fallback -> Sage) 시도 등이 가능하다.
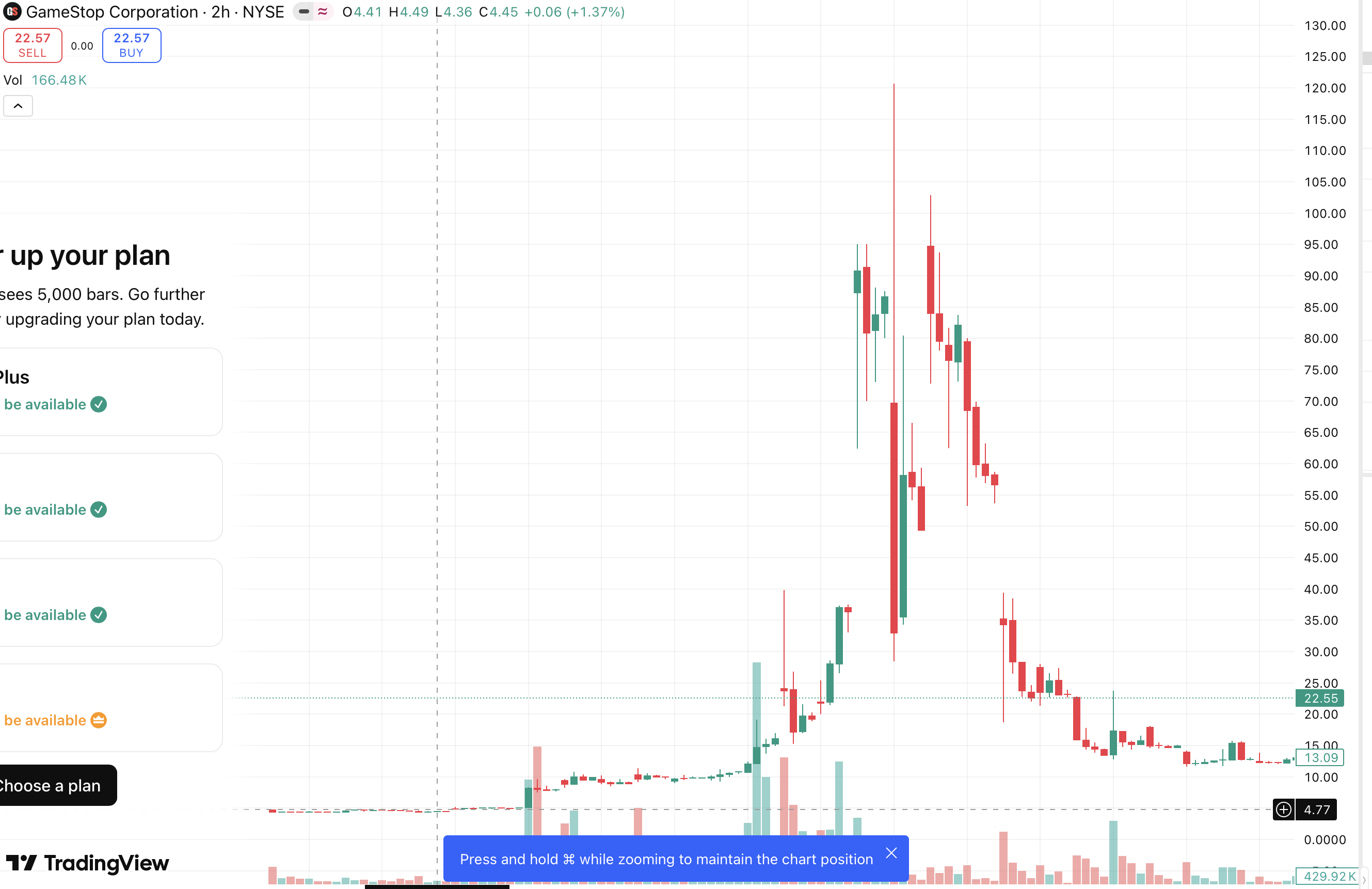
광기의 그래프가 보이는가? 저게 주가 변동이다. 20210129그날 5달러대였던 주식이 120달러(24배) 너머까지 왔다갔다 하고 내려오는 등 엄청난 공방이 오갔다. 나는 이 게임스탑(GME) 사태에서 서킷브레이커라는 용어를 들어봤었다. 일정치 이상의 폭등/락이 일어났을 때 주식 시장에서는 시장을 잠시 닫는다(Close). 이때 개인 투자자(개미)들은 Long(Buy)을 쳤고, 기관투자자들은 공매도로 Short(Sell)을 쳤다. 아마 5분이내 5~10% 오르거나 내리면 서킷브레이커(LULD, Limit Up Limit Down)가 발동한다. 저 차트로 보면 계속 서킷브레이커가 발동한거다. 그리고 수초나 수 분간 일시 정지를 한다.(Half-open) 그리고 다시 시작하고(Closed) 서킷 브레이커 발동(Open)하는 게 수차례 이뤄졌다. 이 방식과 MSA 서킷브레이커와 유사하다.
| 주식시장 | MSA 시스템 |
| 거래 요청 폭주 | API 요청 폭주 |
| 가격 급등/급락 | 서비스 장애 |
| 거래소 중단 | Circuit Breaker OPEN |
| 일정 시간 후 재개 | HALF-OPEN |
| 정상 복귀 | CLOSED |
주식 시장에서는 시장 붕괴 방지용이라면 MSA는 서비스 붕괴 방지다. 컨셉은 거의 같다. 전기 차단기도 비슷할 것이다. Open하면 전선 연결 끊겨서 차단되고 half-open은 준비상태고, closed면 정상 작동하는 스위치랑 비슷하다. (생각이 꼬리를 물어 전선으로 어떻게 빛의 속도로 전파가 전달되냐로 더 얘기할 수 있는데 안하겠다.)
[1-7 API GW]

API Gateway는 클라와 Micro Services 사이의 단일 진입점 역할 하는 서버이다. 클라의 요청 받아 백엔드 서비스로 라우팅하거나 모니터링, 필터로 요청을 인증인가, 인증 인가가 필요하지 않은, 혹은 서비스단까지 필요하지 않은 경우 미리 게이트웨이에 로깅 등을 하는 필터 등을 설정할 수 있다. URL 패턴에 따라 동적으로 라우팅하고, 전후에 작업을 수행하는(pre/post) 필터링, 로그 및 메트릭으로 서비스 상태 모니터링, 요청 인증 인가 검증하는 보안 기능이 존재하는 것이 특징이다. 동적 라우팅에서는 라우트 식별자 이름으로 로드 밸런싱 된 서비스로 해당 경로를 묵어서 특정 라우트로 처리가 가능하다. 게이트웨이도 클라로 등록한다. 필터에는 Global과 특정 라우트만 적용하는 Gateway가 있다. 그래서 필터를 체인처럼 순서를 지정하고 다음 필터로 전달하며, pre/post로 전후에 실행하는 기능을 넣는다. post 에서는 then 이후 람다를 적용하는 방식을 주로 사용한다. 스프링 2 버전 이하는 Zuul을 사용하기도 한다. 실습에서는 상품으로 접속했을 시 포트가 RR(Round Robin)되며 호출마다 필터가 작동하게 했다.
실습에서는 reactive로 했는데, import 시 구분해서 해야된다. 리액티브 웹 애플리케이션으로 임포트를 지속적으로 수정했다. 그리고 GW 의 application.yml 파일도 수정했다. 기존 것이 deprecated (지원 안되는) 강의 자료였는데, 라우트와 디스커버리 설정을 변경했다.
server:
port: 19091 # 게이트웨이 서비스가 실행될 포트 번호
spring:
main:
web-application-type: reactive # Spring 애플리케이션이 리액티브 웹 애플리케이션으로 설정됨
application:
name: gateway-service # 애플리케이션 이름을 'gateway-service'로 설정
cloud:
gateway:
server:
webflux:
routes: # Spring Cloud Gateway의 라우팅 설정
- id: order-service # 라우트 식별자
uri: lb://order-service # 'order-service'라는 이름으로 로드 밸런싱된 서비스로 라우팅
predicates:
- Path=/order/** # /order/** 경로로 들어오는 요청을 이 라우트로 처리
- id: product-service # 라우트 식별자
uri: lb://product-service # 'product-service'라는 이름으로 로드 밸런싱된 서비스로 라우팅
predicates:
- Path=/product/** # /product/** 경로로 들어오는 요청을 이 라우트로 처리
discovery:
locator:
enabled: true # 서비스 디스커버리를 통해 동적으로 라우트를 생성하도록 설정
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/ # Eureka 서버의 URL을 지정
다음과 같이 작성하여 해결하였다. 이제 게이트웨이에서 product나 order로 접속하면 라우팅을 해주는 알고리즘으로 동작한다. predicates 항목을 보면 알 수 있다. product 로 접속하면 로드밸런싱하여 서버를 라운드 로빈해준다.
PreFilter는 요청이 처리 되기 전에 실행되고 PostFilter는 응답을 하기 전에 실행된다. 강의에서는 로그만 처리했다. Logger으로 해결했고, Log4j는 안썼다.
getOrder()같은 부분에서도 @Override를 사용해서 우선순위를 지정했다. preFilter같은 경우에는
return Ordered.HIGHEST_PRECEDENCE;을 하여 우선순위를 높게 지정하였고(-21억 어쩌고 int 처음), PostFilter같은 경우는
return Ordered.LOWEST_PRECEDENCE;으로 우선순위를 낮게 지정하여(21억 어쩌고 int 마지막)
요청 → PreFilter(가장 먼저) → ... 다른 필터들 ... → PostFilter(가장 나중에) → 응답
를 설정하였다.
그리고 build.gradle도 서블릿/리액티브 충돌이 있었는데 해결했다. spring-boot-starter-web 를 제거해서 해결하였다.
또한 SeverHttpRequest를 서블릿용으로 import 하고 있어서 ClassCastException이 발생했는데, reactive로 임포트했더니 해결됐다.
정리하자면, GW에서 잘 못하면 터지는 것은 인증 로직 서비스, 서비스 직접 노출(보안), 클라이언트가 서비스 위치 알아야하거나, 요청 흐름 통제 불가의 문제가 있다. GW 는 SPOF 에 취약하다. 이를 해결하기 위해 LB 로 여러 개의 GW를 사용하는 법이 있다. 라우팅은 URL 엔드포인트 기반으로 클라이언트가 서비스 직접 호출하기보다 GW를 통해서 하게 한다. 필터는 pre/post가 있고, 요청 전/응답 전 처리하여 서비스로 안가도 되는 요청을 걸러낸다. 인증 실패 시 GW 컷, Rate Limit(로깅) 초과 시 GW단 컷.
로드 밸런싱으로 GW 여러 인스턴스 분산하여 트래픽 분산한다. Eureka 연결 시 서비스 위치 몰라도 된다.
질문/답변 리스트
어디 터짐? -> GW 과부하
무엇을 보호? -> Backend 서비스 + 인증 로직 + 네트워크
어디 위치? -> Client와 서비스 사이
언제 필요? -> 서비스 많고 인증/라우팅 복잡할 때
언제 안써도 되냐? -> 단일 서비스/작은 트래픽
Trade-off? -> SPOF 위험 + latency 증가
[1-8 MSA 보안]

문제: MSA 환경에서는 서버가 여러개로 분산된다. 여기서 인증을 어디서 처리할 지 문제가 발생한다.
인증을 서비스마다 하면 - 인증 로직 중복, 성능 낭비(JWT 매번 검증), 보안 정책 불일치, 유지 보수 어려움의 문제가 있다.
즉, 인증 분산을 하면 시스템이 불안정해지는 문제가 있다.
해결: Client -> API Gateway(JWT 검증) -> Service(비즈니스 로직) + Auth Service(토큰 발급)
흐름은 다음과 같다. 로그인 요청 -> Auth Service -> JWT 발급 -> 요청 시 Header에 JWT 포함 -> GW에서 검증 -> 통과 시 서비스 전달
즉, 인증은 GW에서, 서비스는 비즈니스만 한다.(혹은 인가는 서비스에서 따로 구현 정책도 가능하다)
권한 처리 전략에서 GW에서 처리 시 중앙화, 서비스 단순화, GW 뚫리면 전체 뚫림의 장단점이 있고, Service에서 처리할 시 세밀한 권한 제어, 중복 발생의 장단점이 있다. 과거 프로젝트에서 Error는 도메인 별로 분리했는데, 권한도 분리하는 것이 각 도메인이 커졌을 때는 좋지 않나 싶다.
JWT 정보: Stateless(서버에 상태 저장X), 토큰 자체에 정보 포함(id, role 등), 서명기반 -> 변조 불가능
헤더, 페이로드(정보 보이는 보안문제), 서명/ claim을 포함하여 사용자에 대한 정보 전달(id, 권한 등)
특징으로는 자가 포함, 간결성, 서명 및 암호화로 무결성 및 인증 -> 내부 데이터보다 토큰으로, 누가 변조했는지 그대로 가져왔는지 중요함 -> JWT 수정하면 통과 X
MSA에서는 서버가 여러 개라 세션 공유하면 세션 데이터가 비대해질 수 있어서 세션 공유가 어려울 수 있어, JWT가 적합하다 판단했다.
API GW 보안 관점 역할: JWT 검증, 요청 차단(비로그인), 권한 체크 일부 수행, 로깅 / 모니터링 -> 서비스까지 가지 않게 막음
보호 대상은 Backend 서비스, DB, 인증 로직이다.
Trade-off: GW 인증을 할 시 중앙 통제, 성능 절약, 구조 단순화의 장점이 있고, SPOF 위험, 보안 시래 시 전체 영향의 단점이 있다.
그래서 HTTPS, 내부 네트워크 보호(Private), Gateway 다중화 등으로 부분 해결할 수 있다.
추가 보안 포인트: JWT 문제로 Payload에 Base64 쓰면 내용이 보인다. 민감 정보를 넣지 않는 등 부분적 해결을 할 수 있고, 서비스 직접 호출 방지로 방화벽, 내부 네트워크, Gateway만 public을 할 수 있다.
시스템 관점 : API GW는 인증 서버X 검증서버O, Auth Service는 토큰 발급 서버
JWT는 세션 대체 수단 -> 분산 시스템 유리한 인증 방식
세부적 인증 인가 위치 결정은 아키텍처 관점 잘 따지고 해야한다.
현재까지 GlobalFilter 실행 순서
요청 → CustomPreFilter (HIGHEST_PRECEDENCE, 가장 먼저, 요청 URI 로깅)
→ LocalJwtAuthenticationFilter (JWT 검증, /auth/signIn은 bypass)
→ 라우팅 → downstream 서비스
→ CustomPostFilter (LOWEST_PRECEDENCE, 가장 나중에, 응답 status 로깅)
→ 응답
AuthConfig -> Spring Security 설정 — CSRF 비활성화, /auth/signIn permitAll, STATELESS 세션
AuthService -> JWT 생성 — HS512 서명, user_id/role 클레임, 1시간 만료
트러블 슈팅:
1. GW에서 Product 가져오기 503 에러 : Eureka, order-service, product-service 실행 순서/미실행 -> 모든 서비스 순서대로 기동 후 Eureka 등록 대기
2. SignatureAlgorithm.HS512 deprecated 경고 : jjwt 0.12.x에서 enum deprecated -> Jwts.SIG.HS512로 변경
3. AuthConfig deprecated 경고 : Spring Security 6.x에서 authorizeRequests() deprecated -> authorizeHttpRequests()로 변경
4. /auth/signIn 401 에러 : LocalJwtAuthenticationFilter에서 모든 요청에 토큰 검증 적용 -> /auth/signIn 경로 bypass 로직 추가
5. LocalJwtAuthenticationFilter 컴파일 에러 : Jws.parser() 으로 Jwts로 설정 안함(받는건 Jws) -> Jwts.parser() 수정
6. Connection timeout - 500 (172.30.1.76:19094) : Eureka가 macOS 네트워크 IP로 인스턴스 등록, 해당 IP로 접근 불가 -> eureka.instance.prefer-ip-address: true + ip-address: 127.0.0.1 으로 로컬로 설정
7. product-service 503 에러 : Gateway의 Eureka 클라이언트가 최신 레지스트리 미반영 -> GW 포함 전체 재시작, 30초 대기 후 가능
코드 요약:
1. Gateway 설정
- application.yaml
→ routes 및 discovery 설정을 server.webflux 하위로 이동
→ JWT secret-key 추가
- build.gradle
→ spring-boot-starter-web 제거 (Reactive Gateway 사용)
→ netty-resolver-dns-native-macos 추가
2. Gateway 필터
- CustomPreFilter
→ reactive.ServerHttpRequest import로 수정
→ 불필요한 캐스팅 제거
- LocalJwtAuthenticationFilter
→ @Component 등록
→ /auth/signIn 경로 bypass 처리
→ Jwts.parser() 방식으로 수정
→ 예외 처리 추가 (검증 실패 시 401 반환)
3. Auth 서버
- AuthService
→ HS512 서명 방식 적용 (Jwts.SIG.HS512)
→ @Value 설정 오류 수정
- AuthConfig
→ authorizeHttpRequests()로 변경 (Spring Security 6 대응)
→ Stateless 설정 유지
4. 서비스 설정
- product / order
→ eureka.instance.ip-address = 127.0.0.1 설정
→ 로컬 환경에서 통신 문제 해결
개선 가능 포인트:
문제1: 현재 각 서비스로 접속 가능 -> 서비스 보안, 분산 관리 어려움
개선 : 방화벽을 적용하여 GW만 통과하도록 해야함
문제2: Secret Key 관리 하드코딩, GW, Auth 중복 -> 보안 취약, 관리 어려움
개선 : 환경 변수 혹은 Config Server로 중앙관리 - 보안 설정 코드가 아니라 인프라 레벨 관리
문제3: JWT 검증 bypass 방식 signIn에 하드코딩 -> 확장성 낮음, 유지보수 어려움
개선 : whitelist를 yaml로 관리
문제4: SecretKey 생성 validateToken마다 Key 생성 -> 불필요 비용, 성능 낭비
개선 : @PostContructfh 1회 생성 후 캐싱하기 -> 반복 연산 제거하여 성능 최적화
문제5 : 로드밸런서 캐시(기본) -> 성능 제한
개선 : Caffeine 캐시 적용
문제6 : ADMIN 고정 Role 하드코딩 -> 실제 서비스 불가능
개선 : DB 기반 권한 관리하기(권한을 데이터로)
-> 보안, 설정, 성능 요소를 코드에서 분리하고 운영 가능 구조로 개선
너무 depreciated 된 코드가 많더라. 최신화하여 다시 코딩한 것들이 꽤 된다. 트러블 슈팅에 적었다. Talend 라는 크롬 확장을 쓰기도 했는데, 앱을 굳이 들어가서 하지 않는다는 점에서는 포스트맨보다 나은 것 같다.
[1-9 Config 서버 구현]

문제: yml파일에서는 설정 정보나 필요 데이터(@Value 매핑하는) 정보를 담고 있고, MSA 환경에서는 서비스마다 applicaiton.yml을 따로 관리한다. -> 설정 변경 시 모든 서비스 수정 필요, 환경 분리(dev, test, prod) 어려움, 운영 중 설정 변경 불가능 -> 설정이 분산되어 운영이 힘들다.
해결: 설정을 코드에서 분리하고 중앙에서 관리한다. 다음과 같은 구조이다.
Config Server (:18080)
├── native 프로파일 (로컬 파일 기반)
├── config-repo/
│ ├── product-service.yml
│ └── product-service-local.yml
└── Eureka 등록 (CONFIG-SERVER)
Product Service
├── configserver: 로 설정 import
├── Eureka로 Config Server 탐색
├── local 프로파일 적용
├── @RefreshScope 적용
동작 흐름: Product Service 실행 -> configserver import 감지 -> Eureka -> Config Server 위치 조회 -> Config Server 호출 -> 설정 파일 병합 (default + profile) -> 서비스 실행 (서비스 시작 시 외부 설정 주입)
설정 동적 갱신 (@RefreshScope) 과정
Config Server의 config-repo 파일 수정 -> Product Service에 POST /actuator/refresh 호출-> @RefreshScope 빈 재생성 -> message 등 @Value 값 갱신 -> 서비스 재시작 없이 설정 반영
트러블 슈팅:
문제1: ConfigClientFailFastException : config 서버 연결 실패로 서비스 기동 실패 -> configserver import는 fail-fast -> 서버 없으면 바로 죽음
해결 : 기동 순서로 유레카 -> Config Server -> Service
문제2: 포트 충돌 : Docker 컨테이너 점유
해결 : docker stop
Config Server가 보호하는 것 : 설정 일관성, 배포 안정성, 운영 편의성
Config 서버가 죽으면? -> 서비스 시작 불가 -> Config Server SPOF 가능!
그 외에도 설정 오류 시 전체 장애, 복잡도 증가의 문제
지금까지 배운 것과 연결하여 Config 설정할 수 있는 부분 : JWT secret-key, Gateway routing, DB 설정
[1-10 분산 추적]

문제: MSA 환경에서는 하나의 요청이 여러 서비스를 거쳐서 처리된다. (ex. Client → Gateway → Order → Product → User)
여기서 응답이 느려졌을 때 어디가 문제인지 알 수 없다. 응답이 5초 걸렸다 했을 때, Order 문제인지, Product 문제인지, DB 문제인지 불분명하다. 즉, 문제가 있는데 무슨 문제인지 위치를 모른다는 것이다.
해결: 분산 추적을 통해 서비스 간 요청 흐름을 추적한다.
분산 추적 개념 :
Trace : 하나의 요청이 시작부터 끝까지 서비스 거치는 요청 흐름이다. 하나의 트레이스는 여러 스팬으로 구성된다. 클라이언트 요청이 여러 서비스로 전달될 때 각 서비스 호출이 트레이스의 일부이다. 트레이스 ID는 각 스팬에 공통으로 부여된다.
Span: 분산 추적 가장 작은 단위로, 개별 작업 또는 요청이다. 시작 시간, 종료 시간 기록하여 지속 시간 나타낸다. 고유 ID가 있고, 부모 자식 관계 계층 구조를 가질 수 있다. 메타데이터(태그, 로그, 이벤트 등)를 추가해서 상세 정보 기록할 수 있다.
Context: 서비스간 요청이 전달될 때 함께 전파되어 서비스가 요청 전체 흐름 정보 가질 수 있다. 트레이스 ID, 스팬 ID, 부모 스팬 ID를 포함하여 서비스가 요청 출처와 경로를 추적할 수 있게 하고, 분산 시스템에서 컨텍스트 유지로 일관된 추적이 가능하다.
Micrometer : 메트릭+추적 데이터 생성 프로그램
Zipkin : Trace 수집 -> 저장 -> 시각화
흐름:
Client 요청 → Order 서비스 → Trace 생성 → Product 호출 → Span 생성 → Context 전달 (Trace 유지) → Zipkin으로 데이터 전송 → UI에서 확인
Trade-off: 장애 위치 바로 파악, 성능 분석 가능하지만, 성능 오버헤드, 저장 비용 증가, 설정 복잡의 문제가 있다.
분산 추적은 요청의 흐름이나 장애를 시각화하여 빠르게 찾게 도와주는 도구다.
[1-11 이벤트 처리]

문제: 기존 구조는 Order -> Payment (Feign, HTTP) 같이 결제가 죽으면 Order도 실패하고 장애를 전파한다. CircuitBreaker는 차단만 하지 근본 해결이 아니다.
해결: Event Driven으로 비동기적으로 처리가 가능하다. 서비스 간 연결을 끊어 쓰레드, 커넥션, 전체 시스템 안정성을 확보할 수 있다. 기존에는 HTTP로 Thread 잡고 대기하여 서버 터지는 문제가 있었는데, Event로 큐에 넣고 끝 -> 서버 살아남음.
본질: 이벤트 드리븐으로 요청을 바로 처리하지 않고 버틴다. 트래픽 폭증, 느린 서비스 존재, 장애 전파 막아야할 때 이 패턴을 사용한다.
개념:
이벤트 : 시스템에서 발생한 상태변화를 의미하는 메시지 (무슨 일이 발생했다 알리는 것, 요청이 아니라 결과임)
이벤트 소스: 이벤트를 발생시키는 주체 -> 이벤트 생성(Producer 역할)
이벤트 핸들러: 이벤트 받아서 처리하는 주체이다. 이벤트를 보고 각자 알아서 처리한다.
이벤트 버스(Kafka는 Queue): 이벤트 전달하는 브로커같은 중간 시스템, Kafka/RabbitMQ 가 있다. 서비스 간 직접 연결을 끊는 역할을 한다.
Producer: 이벤트 발행하는 쪽
Consumer: 이벤트 받는 쪽. Producer는 Consumer를 모른다!
Spring Cloud Stream: 메시지 버스를 추상화하는 프레임워크이다. Kafka / RabbitMQ 코드 직접 안 다루기 위해 존재한다.
핵심 특징:
Binder 추상화로 Kafka / RabbitMQ를 동일한 인터페이스로 사용한다. 즉 DI로 코드 변경 없이 브로커 교체가능하다.
Producer / Consumer 모델으로 이벤트 생산/소비 구조를 표준화한다. annotation, function기반으로 이벤트 흐름을 코드로 표현한다.
유연한 설정으로 application.yml 기반으로 연결 설정한다. topic이름, binder 종류, consumer 그룹같이 코드 수정 없이 메시지 흐름 변경 가능하다.
이벤트 기반 처리 실패 전략: Order 생성할 시 여러 서비스 분산 처리 가정 (배송지 처리, 결제 처리, 상품 처리) 상품만 실패하였다 가정.
부분 성공하는 상태 발생했다. 데이터 불일치 문제가 발생 가능하다. 누가 전체 상태를 책임질까?
Producer (Order)
→ MQ
→ Delivery Consumer
→ Payment Consumer
→ Product Consumer (실패)이 구조에서 각각 독립 처리하는데, Product만 실패 상태를 알면 안된다.
부분 실패를 전체 시스템에 알려야한다. 그리고 처리에 대한 전략을 세워 대응해야한다. 다음과 같은 프로세스가 있다.
1. 상태전파 필요 : 결제 취소 필요, 주문 롤백 필요, 사용자에게 실패 응답 필요하다.
2. 에러 이벤트 : Product 실패 -> Error 이벤트 발행 (Product → MQ → Error Handler)
3. 에러 처리 시스템 : Error App(또는 DLQ)로 어떤 서비스 실패했는지 기록, 에러 사유 저장, 재처리 대상 관리한다.
4. 재처리/ 복구 매커니즘 : 재시도로 일시적 실패는 다시 처리하거나, 보상 트랜잭션으로 상품 실패 시 결제 취소 이벤트를 발생한다. 즉, 되돌리는 로직이 필요하다. DLQ(Dead Letter Queue)로 처리 실패 메시지 별도 저장하여 장애 분석, 수동 재처리를 하기도 한다.
전체 흐름
Order 생성 (Producer)
→ MQ
→ Delivery Consumer (성공)
→ Payment Consumer (성공)
→ Product Consumer (실패)
→ Error Event 발생
→ Error Queue / DLQ 저장
→ Compensation 발생
→ Payment 취소
→ Order 상태 변경
이벤트 시스템은 모든 작업이 성공한다고 가정하지 않는다. 대신 실패를 어떻게 처리할지를 설계한다.
[결론]
MSA는 단순한 서비스 분리가 아니라, 장애 격리와 확장성을 위한 구조 설계이다. API Gateway, Circuit Breaker, Config Server, MQ 등은 각각 특정 계층의 장애를 막기 위한 장치이다. 특히 인증, 라우팅, 트래픽 제어를 중앙에서 통제하면서도 SPOF를 방지하는 설계가 핵심이다. 동기 호출 구조는 장애 전파를 일으키고, 비동기(Event 기반)는 이를 완화하는 방향으로 사용된다. 결국 MSA는 기능 구현이 아니라 어디서 시스템이 터지는지를 이해하고 막는 아키텍처이다.